File Content Search using FileCloud – Technical Architecture
July 28, 2016
FileCloud is a leading enterprise file access, sync and share solution that provides flexibility to run on-premise or on any IaaS such as AWS, Azure. FileCloud not only has the ability to integrate with cloud storage but also make legacy storage available through its access framework. Additionally, using FileCloud, users can search for files/folders by name, type, date and […]
FileCloud is a leading enterprise file access, sync and share solution that provides flexibility to run on-premise or on any IaaS such as AWS, Azure. FileCloud not only has the ability to integrate with cloud storage but also make legacy storage available through its access framework. Additionally, using FileCloud, users can search for files/folders by name, type, date and size across any storage connected to the system. Furthermore, in v12 release (Q2 2016), FileCloud has increased its search capability by introducing the ability to search files based on its content.
Under the hood, FileCloud uses Apache Solr for searching file contents. This blog explains the interaction between FileCloud and Solr to make content search possible.
Apache Solr
Solr is a highly reliable, scalable and fault tolerant, providing distributed indexing, replication and load-balanced querying, automated failover and recovery, centralized configuration and more. Solr powers the search and navigation features of many of the world's largest internet sites.
Solr is a java application that is packaged with all the components to run it as a standalone service or in a cluster.
FileCloud Integration with Apache Solr
FileCloud can be configured to use Solr as a service to be used for content search. Once FileCloud is configured with Solr, all the uploaded documents (content searchable such as DOC, DOCX, XLS, XLSX, PPT, PPX, PDF, TXT) are indexed by Solr.
Content search consists of two major functionalities:
Indexing of documents and storage of the indexed information.
Querying the index to retrieve files that match the query criteria.
Indexing
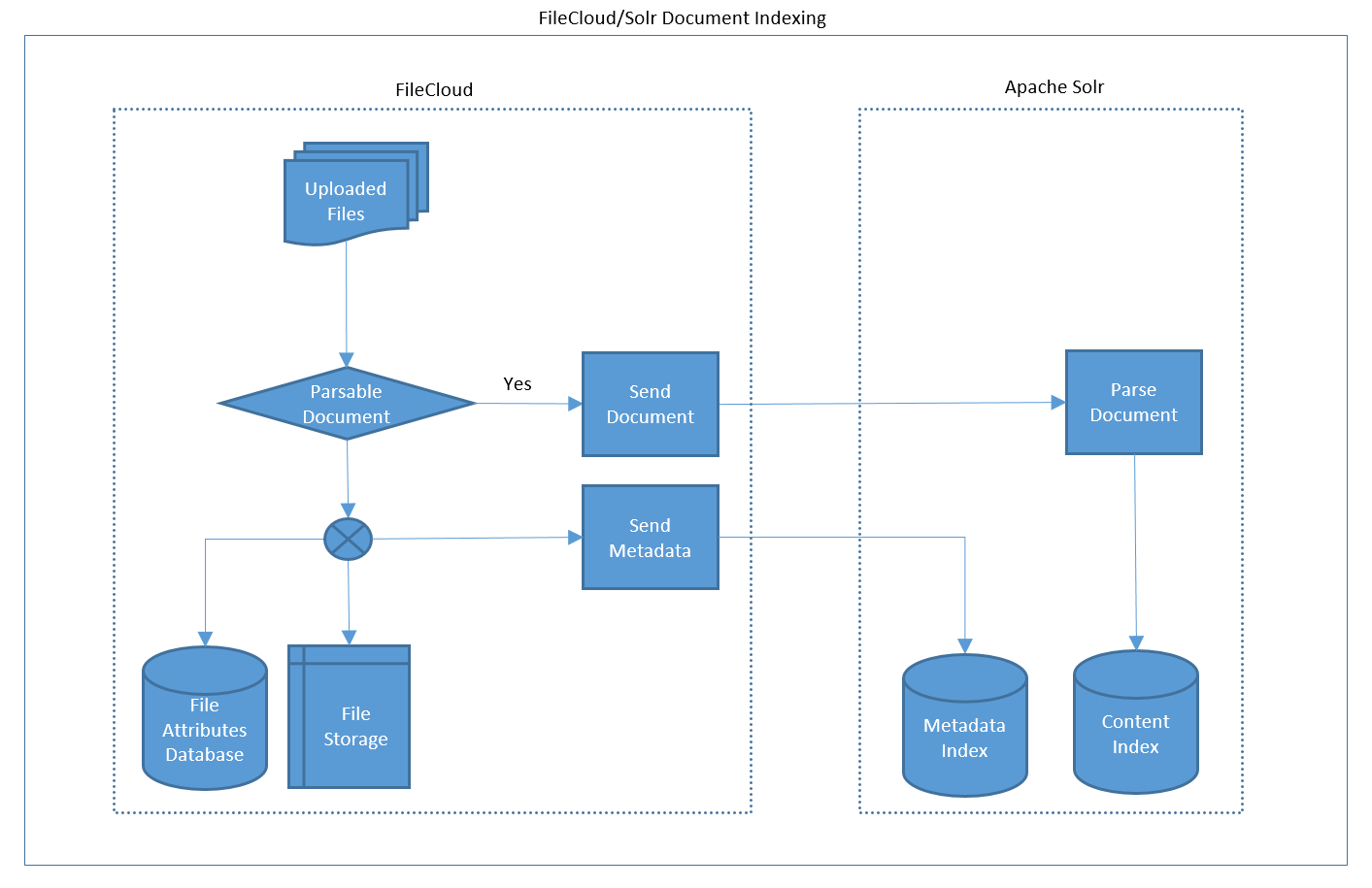
The following is the workflow that happens during indexing of incoming documents:
User uploads a file from any of the client access points such as web browser, FileCloud sync, FileCloud drive, mobile apps, WebDAV client etc.,
FileCloud server checks if the incoming document is a parsable document such as word documents, spread sheets, presentations, plain text files and PDF files.
If the document in not parsable, it is processed and stored in FileCloud. A copy of metadata of the document file is send to Apache Solr, which in turn gets stored in the metadata index. The metadata sent to Solr includes file attributes such as name, path, size, creation date etc. Storing this information in Solr enables FileCloud to retrieve files based on these attributes in addition to content.
If the document is parsable in addition to processing and storing in FileCloud, a copy of the document is uploaded to Apache server. Metadata of this document is also sent to Solr.
When a parsable document is uploaded to Solr, it parses the document, extracts the text contents and stores the information in the content Index.
Querying
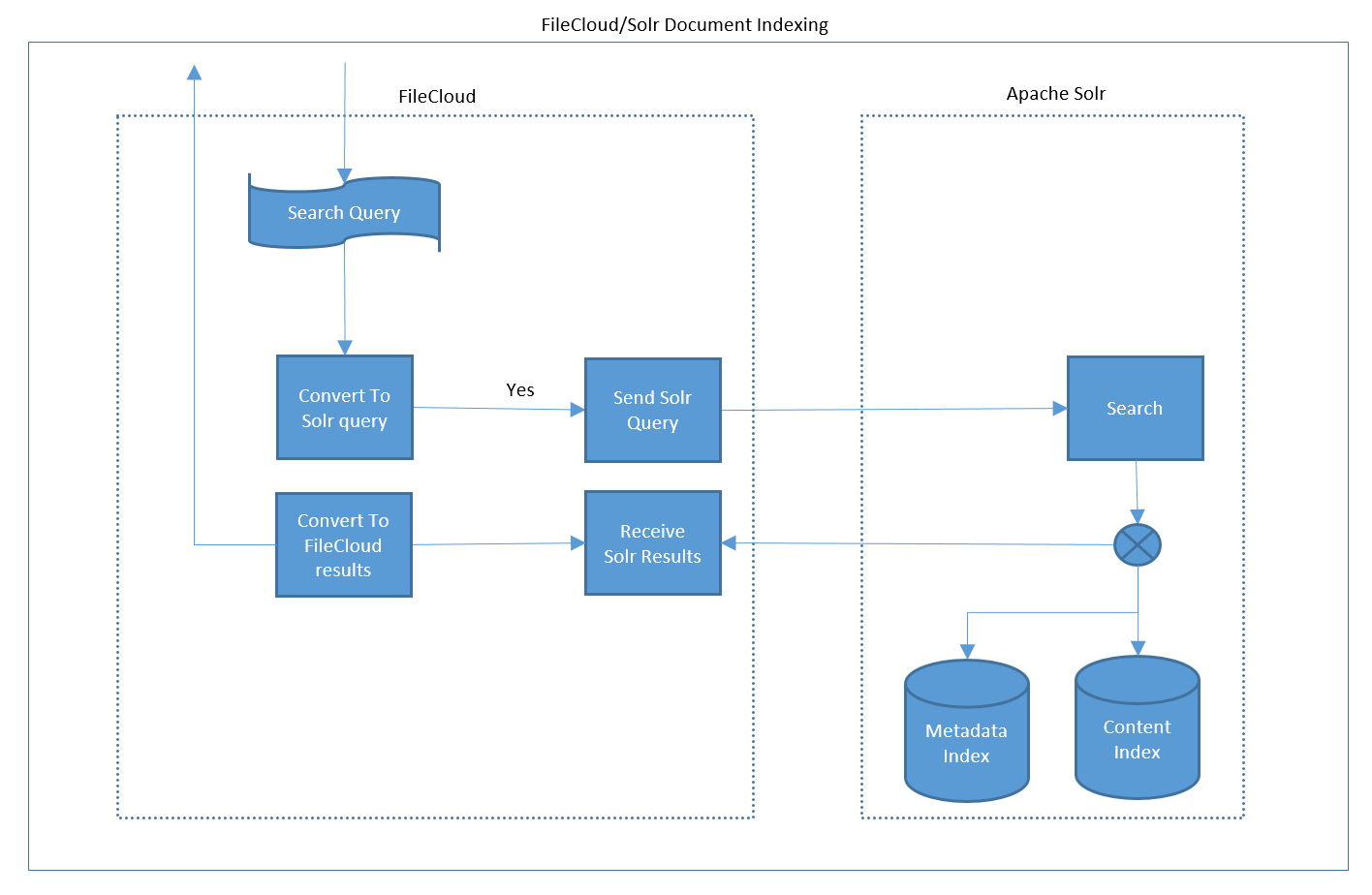
The following is the workflow that happens during querying of files:
Client such as web UI sends search parameters to FileCloud server. The parameters can be some text string to be searched inside the files and/or name, path, size etc.
FileCloud server parses the incoming parameters and converts them to a query format the Solr can understand.
Solr query is then submitted to Solr.
Solr executes the query on the metadata and content index. The results are collected and sent back to FileCloud server.
FileCloud server converts the search results into a XML format understandable to FileCloud clients and sends the result back to the client.